We Have 99% Accuracy in Detecting AI: Originality.ai Study
We believe that it is crucial for AI content detectors reported accuracy to be open, transparent, and accountable. The reality is, each person seeking AI-detection services deserves to know which detector is the most accurate for their specific use case.
The world needs reliable AI detection tools; however, no AI detection tool is ever going to be 100% perfect.
It’s important to understand their limitations so that you can use them responsibly.
What does this mean for developers of AI detectors? They should be as transparent as possible about the capabilities and limitations of their detectors.
At Originality.ai, we believe that transparency is a top priority.
So, below we’ve included our analysis of Originality.ai’s AI detector efficacy, including accuracy data and false positive rates.
Here’s what you’ll find in this guide:
Originality.ai AI Detector model release history
Originality.ai AI Detector accuracy tests
Why is it important for AI detectors to release studies?
How do AI detectors check for accuracy? (learn about confusion matrices)
How AI detection (and the Originality.ai AI Detector works)
Our view: AI detectors in academia and false positives in general
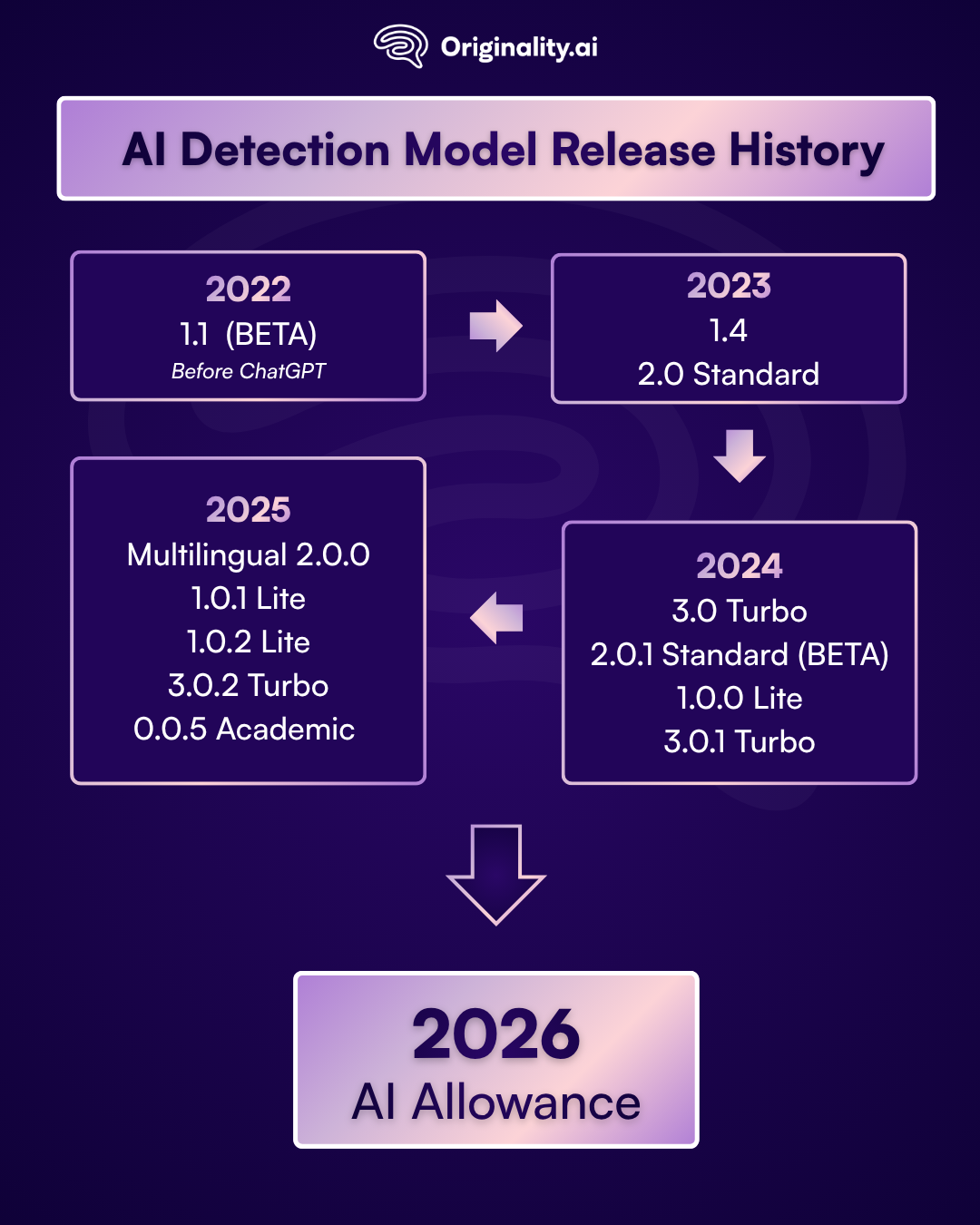
Next generation of Originality.ai AI Detection Models released Sept. 2025:
Lite 1.0.2: 99% accuracy on leading flagship AI models (OpenAI, Gemini, Claude, and DeepSeek), maintains low false positive rates of 0.5%.
Turbo 3.0.2: 99%+ accuracy on leading flagship AI models (OpenAI, Gemini, Claude, and DeepSeek). Robust capabilities in identifying humanized content, up to 97% accuracy. Reduced false positive rates to 1.5%.
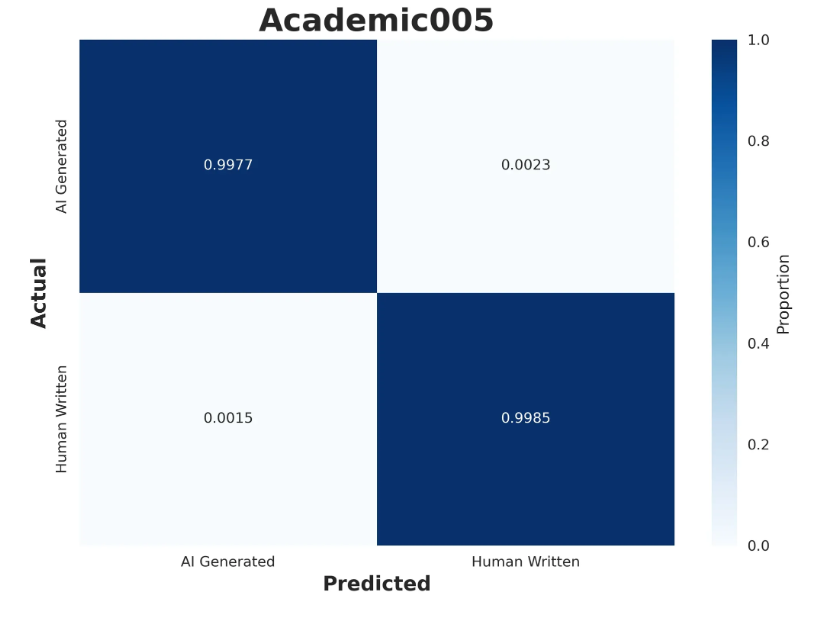
Academic 0.0.5: All-new academic model with 99%+ accuracy and <1% false positives. Ideal for teachers and students.
Major Originality.ai Launches in Early 2025:
Lite 1.0.1 - June, 2025 (now retired): Improved accuracy on leading flagship AI models, low false positive rate; robust at identifying AI Humanizer content.
Multi-Language AI Detector expands to 30 Languages - May 2025: Learn more about our Multilingual AI Detector.
Originality.ai AI Detection Model Release History:
At Originality.ai, our team is always innovating to provide you with the best-in-class AI detection.
Check out our AI detection model release history below:
Originality.ai was the first commercially available AI detector and the first to launch before ChatGPT.
1.1 – Nov 2022 BETA (released before Chat-GPT)
GPT-2, GPT-NEO, GPT-J, and GPT-3 accurate detection. But was able to be “tricked” with Paraphrasing
First GPT-3 trained detector
First commercially available AI detector
1.4 – Apr 2023
Improved ChatGPT detection
Accurate on GPT4-generated content
Only tool capable of accurately detecting paraphrased content.
Reduced the number of false positives with increased training on human-generated content
2.0 Standard — Aug 2023
Reduced False Positives
Improved Accuracy on the Hardest to Detect AI Content (GPT4, ChatGPT & Paraphrased)
Release of Open Source Benchmark Dataset.
Release of Open Source AI Detection Efficacy Testing Tool(s).
Between 1.4 and 2.0, our team built many models, which slightly increased AI detection capabilities, but we weren’t going to release a model until it materially reduced false positives.
September 2024 Update: This model has been retired from our platform. Sign up to try our latest model!
3.0 Turbo — Feb 2024
Trained on the newest LLMs (Grok, Mixtral, GPT-4 Turbo, Gemini, Claude 2)
Accuracy increased on our toughest testing dataset from 90.2% to 98.8%
False Positives have been slightly improved from 2.9% to 2.8%
2.0.1 Standard (BETA) — July 2024
Improved version of the flagship 2.0.0 Standard model (BETA).
September 2024 Update: Thank you for your feedback! BETA testing has now concluded, and with Lite being your top choice, this model has been retired.
1.0.0 Lite — July 2024
Highly accurate with 98% accuracy (under 1% false positive rate).
Allows for lightly AI-edited content (like Grammarly’s grammar and spelling suggestions) while still differentiating between light AI editing and fully generated AI content.
3.0.1 Turbo — October 2024
99%+ accuracy in detecting AI content (under 3% false positive rate).
Best for use cases where there’s a0 tolerance policy for AI content.
Robust against bypassing methods — extremely challenging to bypass.
Multilingual 2.0.0 — May 2025
The Originality.ai Multi Language 2.0.0 model now supports 30 languages!
Notable improvements with an overall accuracy of 97.8%
Reduced false negatives to 1.99% and lowered false positive rate to 2.4%
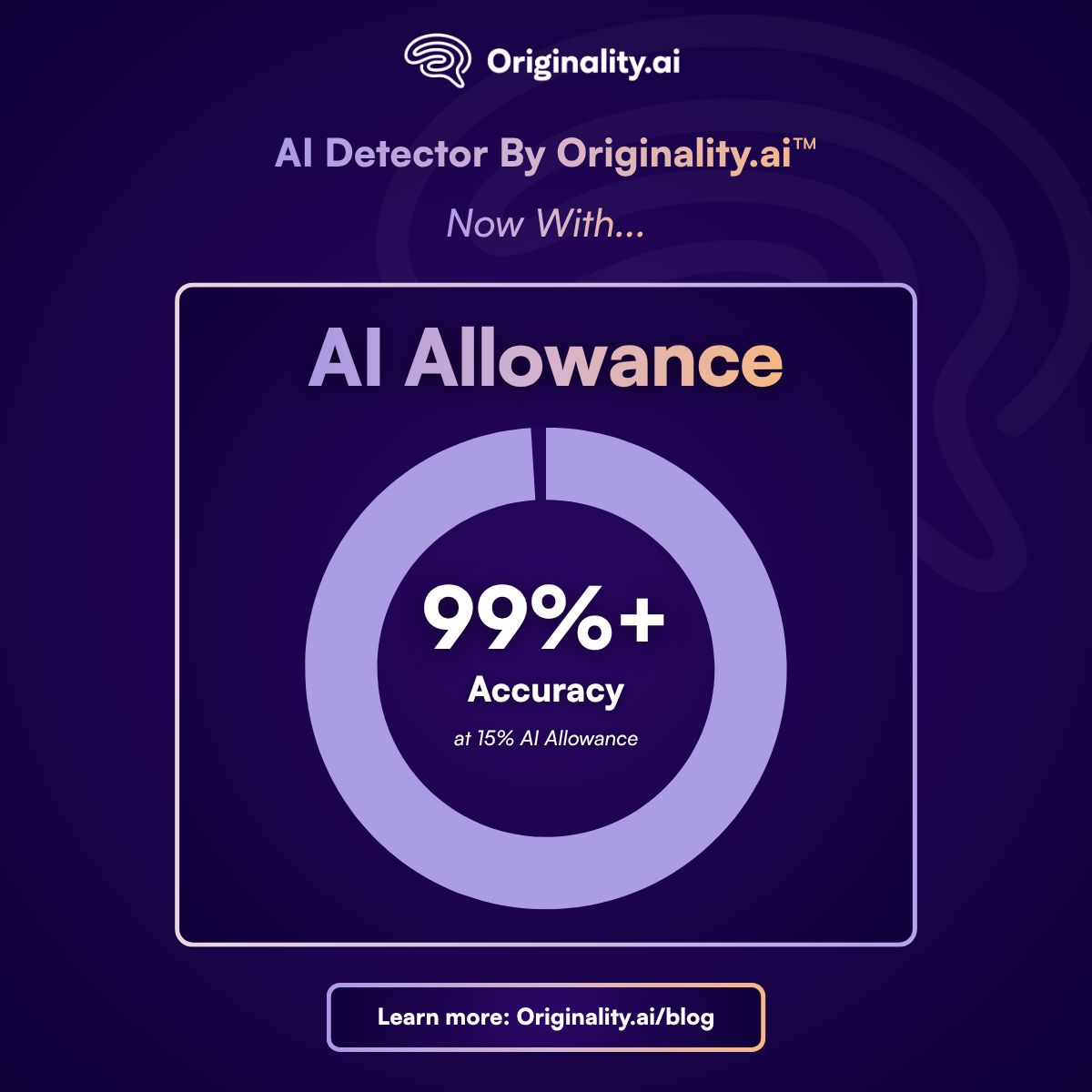
Is AI Allowance an accurate way to check for AI? To answer that question, our machine learning engineers provided a technical breakdown below!
How Do You Measure the Accuracy of "Allowance"?
Measuring the accuracy of AI Allowance requires a fundamentally different approach than traditional AI detection.
To be fully transparent, we evaluate AI Allowance across different types of datasets to understand its performance. It’s important to understand the difference between our classic binary models (like Turbo 3.0.2 and Lite 1.0.2) and the new AI Allowance model.
Binary Models (Turbo & Lite): These models ask one question: "Is this AI or Human?" They produce one consistent label per sample.
AI Allowance (Threshold Model): This model asks: "How much of this is AI?" It measures the content on a spectrum and applies your chosen threshold to make a decision.
Because they do different jobs, comparing them isn't about proving which model is "better" - it's about providing a relative baseline so you can choose the right tool for your specific needs.
The True Test: The Threshold Benchmark
To accurately test AI Allowance, we built an entirely new Internal Combined Benchmark (167,980 samples) containing spectrum data.
In a traditional dataset, a text is either "Human" or "AI." But in our Threshold Benchmark, the "correct" label of a single sample actually flips depending on the threshold you choose.
Here is how that works in practice:
Imagine a 1,000-word human-written article where the writer used AI to generate 100 words (10% AI).
If you select 5% AI Allowance: The correct label for this text is Likely AI, because 10% exceeds your strict 5% limit.
If you select 15% AI Allowance: The exact same text's correct label flips to Likely Original, because 10% is safely within your moderate 15% limit.
On this specialized spectrum benchmark, AI Allowance excels at dynamically identifying the degree of AI used, achieving 96.53% overall accuracy at the strict 5% boundary with highly balanced precision and recall.
Understanding Our Traditional Dataset (Benchmark V6)
We also tested AI Allowance against our massive Benchmark V6 dataset (specifically, a 456,872-sample slice of modern flagship models like GPT-5, Claude 4.5, and Gemini 2.0).
It is crucial to note that Benchmark V6 is a traditional binary dataset. In V6, whether a text was 5% AI-generated or 40% AI-generated, it was simply labeled as "AI-generated."
When you look at the V6 accuracy table below, you will see the highest overall accuracy at the 15% threshold. This does not mean 15% is a "better" threshold than 5% or 25%. It simply means that 15% AI Allowance is the boundary that most closely aligns with how "AI-generated" content was historically defined and labeled in traditional datasets.
Here is how AI Allowance performs on the V6 dataset alongside our classic models as a relative baseline:
Model / Threshold
Overall Accuracy
Precision (Trust in the AI flag)
What This Means
AI Allowance (5%)
98.0%
91.1%
Highly sensitive. Will flag even minor AI edits.
AI Allowance (15%)
99.4%
98.5%
Aligns best with traditional definitions of AI content.
AI Allowance (25%)
95.8%
99.7%
Highly precise; only flags heavy AI usage.
AI Allowance (40%)
88.7%
99.8%
Extremely lenient; near-zero false positives.
Lite 1.0.2 (Binary)
99.3%
97.0%
Excellent lightweight baseline for strict binary detection.
Turbo 3.0.2 (Binary)
98.3%
91.8%
Aggressive recall for catching older and newer AI models alike.
The Takeaway: AI Allowance is flexible to your use case; most use cases can benefit from selecting 15% AI Allowance.
If you have a zero-tolerance policy, use 5% AI Allowance or Turbo 3.0.2. But if you want to allow for light AI grammar edits and brainstorming while still catching heavily AI-generated essays or articles, 15% AI Allowance provides incredible precision and flexibility for the modern hybrid-writing era.
Classic Models (Lite, Turbo, and Academic)
Lite 1.0.2, Turbo 3.0.2, and Academic 0.0.5 Accuracy:
As well as the all-new AI Allowance, Originality.ai also offers Classic AI Detection Models: Lite, Turbo, and Academic.
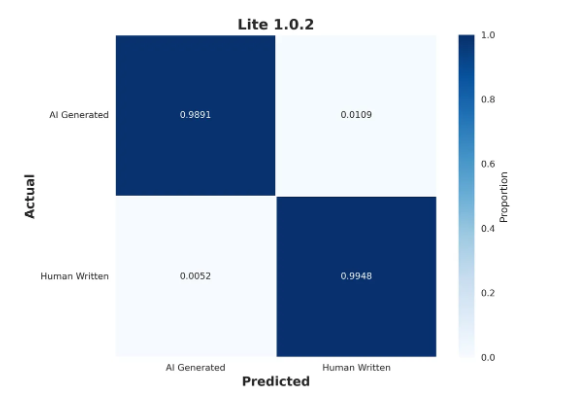
Lite 1.0.2: 99% accuracy across all leading flagship AI models from OpenAI, Gemini, Claude, and Deepseek, and maintains a lower 0.5% false positive rate (in comparison to Lite 1.0.0 = 0.73% FPR).
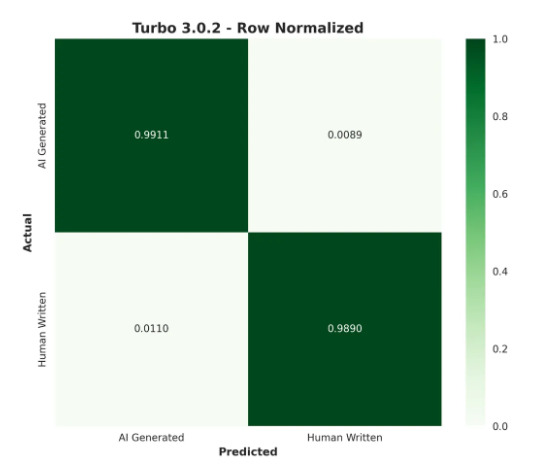
Turbo 3.0.2: 99%+ accuracy across all leading flagship AI models from OpenAI, Gemini, Claude, and Deepseek, and a low 1.5% false positive rate. Robust against AI humanizer and bypasser tools with up to 97% accuracy.
Academic 0.0.5: 99%+ accuracy across leading flagship AI models, OpenAI (GPT-5) and DeepSeek, and a low <1% false positive rate. Robust against AI humanizer and bypasser tools with up to 92% accuracy. Focused on academic content (STEM answers, including code and formulas).
See an overview of their accuracy benchmarks in the tables and confusion matrices below:
Lite 1.0.2, Turbo 3.0.2, and Academic 0.0.5 Accuracy Benchmarks
Then, see Originality.ai AI Detection accuracy by LLM, as well as popular humanizers, for our Classic Models, in the tables below:
Lite 1.0.2, Turbo 3.0.2, and Academic 0.0.5 Accuracy by LLM
LLM
Lite 1.0.2 Accuracy
Turbo 3.0.2 Accuracy
Academic 0.0.5 Accuracy
GPT-5
99.6%
99.8%
99.6%
GPT-4.1-Nano
100%
100%
GPT-4o
99.2%
99.5%
GPT-4.1
99.8%
99.9%
Claude Haiku
99.2%
99.7%
Gemini 2.0 Flash
100%
100%
DeepSeek V3.1 Chat
99.68%
99.9%
99.8%
Lite 1.0.2, Turbo 3.0.2, and Academic 0.0.5 Accuracy on Popular AI Humanizers
Humanizer
Lite 1.0.2 Accuracy
Turbo 3.0.2 Accuracy
Academic 0.0.5 Accuracy
Undetectable.ai
80.3%
92%
82.4%
Phrasly.ai
86.1%
92%
89%
Stealthwriter.ai
87.1%
94%
89.1%
Netus.ai
86.1%
97%
92.1%
Humbot.ai
81.2%
90%
83.3%
The metrics in the tables above were analyzed for the September 2025 launch of these models.
Since then, we have continued testing our models as new LLMs are released. Check out the AI studies below to see accuracy data on some of the latest AI models:
So, now you’ve read the metrics for Originality.ai’s accuracy, but how do AI detectors check for accuracy? Here’s a bit more information for background context.
Below are the best practices and methods used to evaluate the effectiveness of AI classifiers (i.e., AI content detectors).
One single number related to a detector's effectiveness without additional context is useless!
Don’t trust a SINGLE “accuracy” number without additional context.
Here are the metrics we look at to evaluate a detector's efficacy…
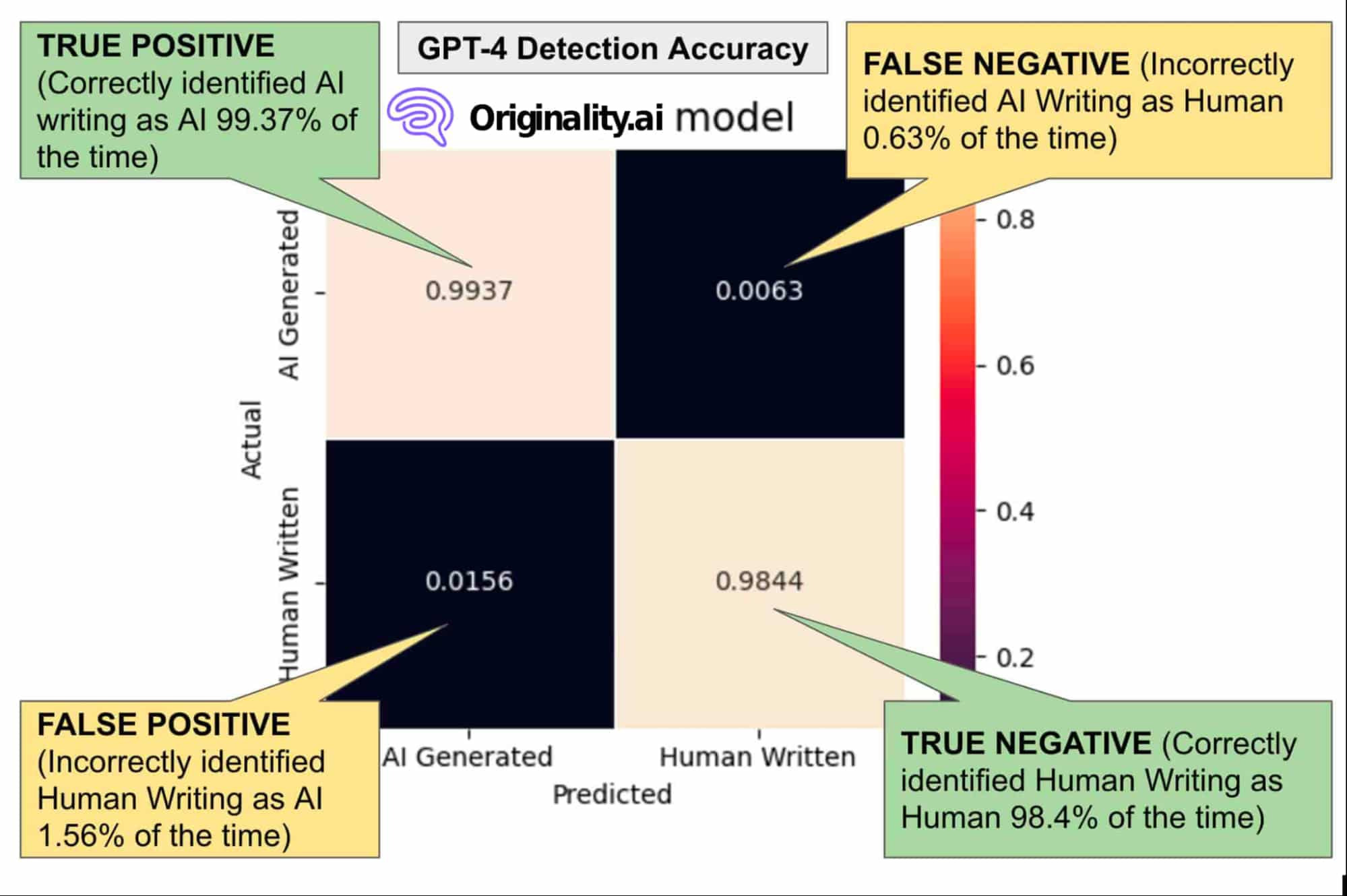
Confusion Matrix
The confusion matrix and the F1 (more on it later) together are the most important measures we look at. In one image, you can quickly see the ability of an AI model to correctly identify both Original and AI-generated content.
True Positive (TP): AI detector correctly identified AI content as AI.
False Negative (FN): AI detector incorrectly identified AI content as human.
False Positive (FP): AI detector incorrectly identified human content as AI.
True Negative (TN): AI detector correctly identified human content as human.
Version 1.4 Confusion Matrix on a GPT-4 & Human Dataset Test
True Positive Rate — AI Text Detection Capabilities
Identifies AI content correctly x% of the time. True Positive Rate TPR (also known as sensitivity, hit rate or recall).
Identifies human content correctly x% of the time. True Negative Rate TNR (also known as specificity or selectivity).
True Negative Rate TNR = TN / (TN & FP) = 1- FPR
Accuracy:
What % of your predictions were correct? Accuracy alone can provide a misleading number. This is in part why you should be skeptical of AI detectors' claimed “accuracy” numbers if they do not provide additional details for their accuracy numbers. The following metric is what we use to measure accuracy.
Combines Recall and Precision to create one measure to rank all detectors, often used when ranking multiple models. It calculates the harmonic mean of precision and sensitivity.
F1 = 2 x (PPV x TPR) / (PPV + TPR) where Precision (PPV) = TP / (TP + FP)
Metrics Considered but Not Used:
ROC & AUROC: Not used since we can't adjust the sensitivity of other tools and some tools do not provide a percentage.
Precision: PPV = TP / (TP + FP) - Not used
Why Is It Important for AI Detectors to Release Studies?
FTC Addresses Unsupported AI Detection Accuracy Claims
Claimed accuracy rates with no supporting studies are clearly a problem.
We hope the days of AI detection tools claiming 99%+ accuracy with no data to support it are over. A single number is not good enough in the face of the societal problems AI content can produce, and the important role AI content detectors have to play.
The FTC has come out on multiple occasions to warn against tools claiming AI detection accuracy or unsubstantiated AI efficacy.
In 2025, the FTC addressed misleading accuracy claims from one company offering AI detection without the data to back it up:
“The order settles allegations that Workado [Content at Scale now BrandWell] promoted its AI Content Detector as “98 percent” accurate in detecting whether text was written by AI or human. But independent testing showed the accuracy rate on general-purpose content was just 53 percent, according to the FTC’s administrative complaint. The FTC alleges that Workado violated the FTC Act because the “98 percent” claim was false, misleading, or non-substantiated.” - Source: FTC
So, we created this guide and tools, because we believe…
In the transparent and accountable development and use of AI.
That AI detectors have a role to play in supporting AI transparency across industries
AI detection tools' “accuracy” should be communicated with the same transparency and accountability that we want to see in AI’s development and use. Our hope is that this study will move us all closer to that ideal.
At Originality.ai, we aren’t for or against AI-generated content… but believe in transparency and accountability in its development, use, and detection.
Originality.ai helps ensure there is trust in the originality of the content being produced by writers, students, job applicants, or journalists.
Pro Tip: Scanning high volumes of content for AI? Check out our Bulk Scan feature.
How AI Detection (and the Originality.ai AI Detector Works)
Our AI detector works by leveraging supervised learning of a carefully fine-tuned large AI language model.
We use a large language model (LLM) and then feed this model millions of carefully selected records of known AI and known human content. It has learned to recognize patterns between the two. More details on our AI content detection.
Below is a brief summary of the 3 general approaches that an AI detector (or called in Machine Learning speak a “classifier”) can use to distinguish between AI-generated and human-generated text.
1. Feature-Based Approach:
The feature-based approach uses the fact that there can potentially be consistently identifiable and known differences that exist in all text generated by an LLM like ChatGPT when compared to human text. Some of these features that tools look to use are explained below.
Burstiness
Burstiness in text refers to the tendency of certain words to appear in clusters or "bursts" rather than being evenly distributed throughout a document.
AI-generated text can potentially have more predictability (less burstiness) since AI models tend to reuse certain words or phrases more often than a human writer would.
Some tools attempt to identify AI text using burstiness (more burstiness = human, less burstiness = AI).
Perplexity
Perplexity is a measure of how well a probability model predicts the next word. In the context of text analysis, it quantifies the uncertainty of a language model by calculating the likelihood of the model producing a given text.
Lower perplexity means that the model is less surprised by the text, indicating the text was more likely AI-generated. High perplexity scores can indicate human-generated text.
Frequency Features
Frequency features refer to the count of how often certain words, phrases, or types of words (like nouns, verbs, etc.) appear in a text. For example, AI might overuse certain words, underuse others, or use certain types of words at rates that are inconsistent with human writing. These features might be able to help detect AI-generated text.
Studies have shown that earlier (ie 2019) LLMs would generate text that has similar readability scores.
Punctuation
This pertains to the use and distribution of various punctuation marks in a text. AI-generated text often exhibits correct and potentially predictable use of punctuation.
For instance, it might use certain types of punctuation more often than a human writer would, or it might use punctuation in ways that are grammatically correct but stylistically unusual. By analyzing punctuation patterns, someone might attempt to create a detector that can predict AI-generated content.
Advantages vs. Disadvantages
Advantages: Once patterns are identified, they can be repeatedly identified in a very cost-effective and fast manner.
Disadvantages: Modern LLMs such as ChatGPT4 and Bard can produce varied enough content that these detectors can be bypassed with clever ChatGPT prompts.
A zero-shot approach uses a pre-trained language model to identify text generated by a model similar to itself. Basically, asking itself how likely the content the AI is seeing was generated by a similar version of itself (note: don’t try asking ChatGPT… it doesn’t work like that).
Advantages: Easier to build and does not require supervised training
A fine-tuning AI model approach uses a large language model such as BERT or RoBERTa and trains on a set of human and AI-generated text. It learns to identify the differences between the two in order to predict if the content is AI or Original.
Advantages: Can produce the most effective detection
Disadvantages: These can be more expensive to train and operate. They can also lag behind in detection capabilities for the newest AI tools until their training is updated.
The test below looks at the performance of multiple detectors using all of the strategies identified above.
Our View: AI Detectors in Academia & False Positives in General
We do not believe that AI detection scores alone should be used for academic honesty purposes and disciplinary action.
The rate of false positives (even if low) is still too high to be relied upon for disciplinary action.
Here is a guide we created to help writers or students reduce false positives in AI content detector usage.
Plus, we created an AI detector Chrome extension to help writers, editors, students, and teachers visualize the creation process and prove originality.
Our Academic model is best for educators and academic settings, as it allows for light AI editing with popular tools like Grammarly (grammar and spelling suggestions) and is designed to be accurate on STEM-related content.
That means helping to maintain AI transparency in content marketing, journalism, education, and more.
Consider a student submitting an assignment. They want to know they can confidently submit that essay or paper and have their hard work recognized.
Both students and teachers benefit from accurate AI detection. Students can be confident that they can prove their work is original, and teachers can have clarity on AI use.
The same is true for writers and editors. A writer submitting a blog post or article wants peace of mind that authentic, human-written work will be recognized, while editors need clarity on the writing process for submitted work.
Here’s how accurate AI detection can benefit you:
Academic Integrity
Students can prove their work is original, such as with our Chrome Extension
Teachers get clarity on AI use, like with our Moodle Plugin
Authentic Content, Blogs, and Articles
Writers can align AI use with AI policy for each publication, using AI Allowance
Integrity in University, Scholarship, and Job Applications
Whether you’re writing or reviewing an application, confidently show (or find out) the origins of a document and check if AI usage matches your standards.
Support for SEOs and Marketers Publishing People-First Content
AI content also has SEO implications. We studied possible Google AI Penalties and found that publishing AI content can carry risks.
In 2025, Google released updated Search Quality Rater Guidelinesstating: “The Lowest rating applies if all or almost all of the MC on the page (including text, images, audio, videos, etc) is copied, paraphrased, embedded, auto or AI generated, or reposted from other sources with little to no effort, little to no originality, and little to no added value for visitors to the website.” - Google
Across 4 LLMs (ChatGPT, DeepSeek, Gemini, and Grok) and human-written samples, Originality.ai had perfect accuracy (100%), precision, recall, and F1-Score.
Turnitin, ZeroGPT, Detecting-AI.com, GPTZero, QuillBot, Grammarly, Sapling, Copyleaks, and Originality.ai
98% overall accuracy and100% specificity on human-written texts
Aidetector, GPTZero, Copyleaks, Originality.ai, Turnitin, and DetectingAI
The end result?
Across both internal testing and third-party studies, we continue to outperform competitors as the Most Accurate AI Detector.
Why Is Our Model Accurate?
Below are a few of the main reasons we suspect Originality.ai’s AI detection performance and overall AI detector accuracy are significantly better than alternatives…
Larger Model: We suspect (can’t confirm) that we use a much larger model… there is no way we could offer a free or ad-supported option given our models' compute cost per scan.
Train on the Latest LLMs: New AI models are continuously being released. We train our AI detector to identify the latest LLMs.
Train on Harder Datasets: The datasets we continue to create and train our AI on focus on increasingly adversarial detection bypassing methods. The better our AI gets, the more clever the prompt engineering or playground settings need to be to bypass us, and then we train on that new, more challenging dataset.
Final Thoughts
The AI/ML team and core product team at Originality.ai have worked relentlessly to build and improve on the most effective AI content detector!
The Results…
Originality.ai offers highly accurate AI detection options in 2026:
AI Allowance: 99%+ accurate at 15% AI Allowed
Lite: high accuracy at 99%, with a 0.5% False Positive Rate
Turbo: 99%+ accuracy, with a 1.5% false positive rate.
Academic: exceptional 99%+ accuracy and a low <1% false positive rate
If you have any questions on whether Originality.ai would be the right solution for your organization, please contact us.
If you are looking to run your own tests, please contact us. We are always happy to support any study (academic, journalist, or curious mind).
We hope this helps establish clarity and transparency around AI detection and AI detection accuracy, and that other AI detectors will also share their accuracy results to further establish transparency in the industry.
Read more about other AI detection tools in our reviews
Below is a list of all AI content detectors and a link to a review of each. For a more thorough comparison of all AI detectors and their features, have a look at this post: Best AI Content Detection Tools
Founder / CEO of Originality.ai I have been involved in the SEO and Content Marketing world for over a decade. My career started with a portfolio of content sites, recently I sold 2 content marketing agencies and I am the Co-Founder of MotionInvest.com, the leading place to buy and sell content websites. Through these experiences I understand what web publishers need when it comes to verifying content is original. I am not For or Against AI content, I think it has a place in everyones content strategy. However, I believe you as the publisher should be the one making the decision on when to use AI content. Our Originality checking tool has been built with serious web publishers in mind!