AI Checker
Plagiarism Checker
Grammar Checker
Content Quality
Guideline Checker
Readability Checker
Fact Checker

Chrome Extension

They may not have the same name recognition as robots.txt just yet, but new AI web standards like llms.txt, llms-full.txt, and ai.txt are quietly emerging to help site owners define how AI interacts with their content.
Like it or not, AI bots, including GPTBot, CCBot, and ClaudeBot, are now actively visiting websites and collecting data to train large language models (LLMs), generate responses, and pull summaries for AI tools.
Although robots.txt has been the standard for controlling how search engine crawlers interact with sites for decades, it was never meant to handle these AI bots. Therefore, some site owners have been adopting the new AI web standards to take back control of their web content.
In addition to tracking their adoption over time, this article will explore the new AI web standards, how to implement them, and their benefits and limitations.
One year into tracking llms.txt, the headline is no longer just that adoption is climbing.
It’s that the companies shaping AI search and agents cannot seem to agree on what llms.txt is actually for.
When it comes to llms.txt, big AI companies say one thing, and then they do another.
Google says search ignores llms.txt, yet Chrome Lighthouse includes an optional agentic browsing audit for llms.txt.
OpenAI and Anthropic advise using robots.txt, yet they’ve both published an llms.txt.
The inconsistency of Google, OpenAI, and Anthropic’s messaging vs. actions around llms.txt is concerning, not to mention confusing for users.
How are users supposed to decide whether it’s beneficial to implement llms.txt when the leading AI platforms can’t seem to?
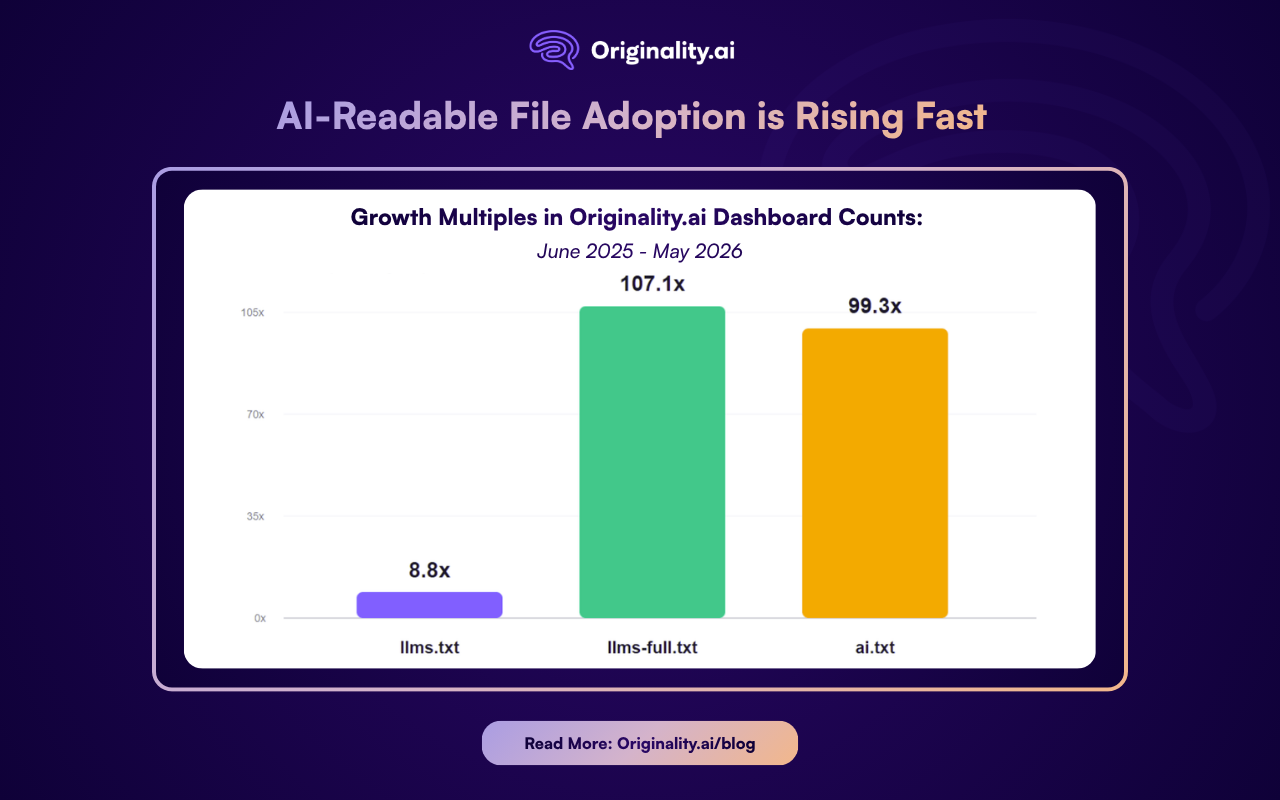
Our tracker recorded 4,088 llms.txt instances 1 year ago, back in June 2025.
By May 2026, that number reached 36,120, an 8.8x increase in twelve months.
Total, counting llms-full.txt and ai.txt alongside llms.txt, our study has now identified 38,980 sites adopting these files across the 3+ million websites analyzed in our dashboard.
The newer formats are growing even faster from far smaller bases...
…over the same period.
These are massive multiples, but still just a fraction of llms.txt’s potential footprint.
A separate study from Ahrefs published in June 2026, drawing on server-log data from 137,000 domains, found that 97% of llms.txt files received 0 requests in May 2026.
That meant they found that almost every llms.txt file they studied went unread.
Even where AI retrieval bots (AI bots that answer user queries in AI search) were active, they accounted for just 1.1% of requests.
How about AI training crawlers?
Ahrefs found that the total crawlers they studied, like GPTBot, ClaudeBot, or DeepseekBot, accounted for just 5.3% of requests. When you get granular, the percentages get even lower:
When requests were made, the biggest requesters of these files were not AI assistants at all, but actually SEO audit tools. The top three bots requesting llms.txt included:
Learn more about AI bot blocking in our dashboard study.
Originality.ai’s research in the context of the Ahrefs study:
So, what does the Ahrefs data mean in the context of our research? Adoption is clearly rising, but usage is another story.
In short, more sites (8.8X more in just 1 year) are adopting llms.txt, but almost nothing is reading it.
Perhaps even more interestingly, the companies defining how AI reads the web are saying one thing about llms.txt, and doing another.
Overview of Google, OpenAI, and Anthropic’s guidance on LLMs.txt:

The key takeaway here? While llms.txt was proposed as a way to give AI models more clarity about a site, even the major AI companies aren’t suggesting you use it to try to improve AI search rankings.
As the table above shows, each of the big three publishes an llms.txt for its own developer documentation, yet none tells site owners to rely on it for AI visibility.
Let’s take a closer look:
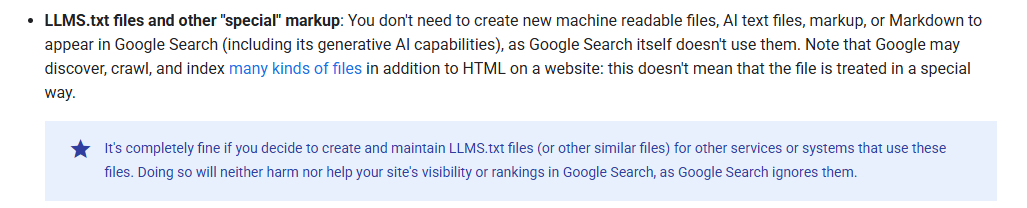
According to Google: “It's completely fine if you decide to create and maintain LLMS.txt files… will neither harm nor help your site's visibility or rankings in Google Search, as Google Search ignores them.”
Then, Chrome Lighthouse offers an audit for agentic browsing for llms.txt that is completely optional.
So, Google notes that llms.txt won’t help SEO (or negatively impact it); those files are simply ignored, but they do offer an agentic browsing option.
What about OpenAI?
They don’t even mention it in their guide on OpenAI crawlers. What they do mention is using robots.txt as the method for managing how a website or content interacts with AI.
Instead, they reference llms.txt in their developer/API docs.
Anthropic’s guide on data crawling also interestingly doesn’t note instructions for llms.txt. Similar to OpenAI, it mentions robots.txt instead, and also like OpenAI, they reference it in their developer/API docs.
With all that in mind, from adoption to usage, where does that leave llms.txt? Is it important? And if so, in what context?
As of May 2026, llms.txt looks far more like AI-readable documentation and agent-readiness infrastructure.
It’s not an AI-search visibility tactic, and the major AI platforms are not pointing to it for visibility. In the broader context of Ahrefs’ data, our tracker shows that adoption is rising, but usage requests are still near 0.
How to approach it in the meantime? Consider it similar to a clean, structured map of your content that coding assistants and agents can parse on demand.
That said, it can still be worth it if you have documentation, APIs, product information, or other content you want agents and AI coding tools to navigate cleanly.
Publish it for agent-readiness, keep your robots.txt and named-crawler controls in place for actual crawler management, and keep an eye on how things evolve over time.
Keep reading to learn even more about llms.txt.
Robots.txt doesn’t reliably control AI crawlers for several reasons:
Overall, the problem isn’t just a lack of features. Robots.txt is based on an outdated idea of what a crawler is, and it simply can’t handle the new challenges of how today’s AI models access and interpret web content.
To address the limitations of robots.txt, new AI web standards are emerging to help give site owners more control over how AI models interact with their content: llms.txt, llms-full.txt, and ai.txt.
What is llms.txt? Proposed by data scientist Jeremy Howard in 2024, llms.txt is a markdown file that allows site owners to help LLMs better understand their content.
Unlike robots.txt, which only allows or blocks crawlers, llms.txt is all about guidance, giving AI models context and clarity about what’s at a given URL. Whether an LLM takes that guidance, though, is up for debate — using llms.txt is completely voluntary, so AI models can choose to ignore it, even if it’s for their benefit.
Placed at a site’s root, llms.txt can include both human- and machine-readable information like:
Because LLMs have limited context windows (or can only process so much information at a time), this kind of high-level guidance can help them focus their efforts on analyzing or summarizing the most relevant or important parts of a site. Otherwise, it leaves them grabbing text at random, which can completely misrepresent what a site’s all about.
Although the adoption of new AI web standards is still fairly low and slow across the board, llms.txt has emerged as the clear frontrunner, suggesting that it may just become the go-to option for guiding how LLMs interact with websites in the future.
Llms-full.txt takes things a step further than llms.txt by offering LLMs access to all relevant content in one place, not just summaries or an index of links. Basically, it makes it even easier for AI models to understand how all the different content pieces of a site come together.
See, llms-full.txt provides LLMs with a full, flattened map of a website. Unlike traditional maps, like sitemap.xml, it includes the actual content, laying out every page and section in a single, readable format to enable AI models to access and understand everything at once. As long as they choose to use it, that is — as with llms.txt, LLM compliance with llms-full.txt is voluntary.
Also like llms.txt, llms-full.txt is placed at the root of a website, and its content is readable to both humans and machines. However, it includes slightly different information:
Since it contains so much text and LLMs have limited context windows, llms-full.txt is best suited for smaller sites or sets of specific, self-contained information, such as a product manual or knowledge base for a single topic. As long as everything in the file can fit into an AI model’s context window, it should be good to go.
Ai.txt is a little different than both llms.txt and llms-full.txt. Instead of guiding AI models on how to interpret your content, ai.txt provides AI crawlers with instructions about what they can and cannot do with it.
Whenever AI bots download content from a website, they’re supposed to read ai.txt files to learn whether site owners permit their work to be used for AI-specific purposes (like training or summarizing). However, the key term here is “supposed to”.
Like robots.txt, llms.txt, and llms-full.txt, compliance with ai.txt is up to the bots and the companies behind them. Spawning, a company actively promoting the standard, notes that AI bots using its API will respect ai.txt, but most do not. At least, not yet.
Until adoption increases or another option starts to gain momentum in the meantime, though, ai.txt is still one of the most effective ways to communicate a site owner’s AI usage preferences.
Simply place the human- and machine-readable ai.txt at the root of a website, and include the following information to specify what AI can do with its content:
Now, don’t let the allow/disallow directives fool you — ai.txt isn’t just about controlling bot access like robots.txt. It builds on that idea for the AI era, giving site owners much more granular control over how AI systems can use, train on, and reuse content.
One of the best things about the new AI web standards in general is that they’re relatively easy to set up, as all you really need is a plain text editor. Other than that, no special tools are required.
Here’s how to get started with llms.txt and how to create an llms.txt file:
To create an llms.txt file, use the following structure (in order) using markdown-style formatting in plain text:
All of the following steps are optional:
With both required and optional elements included, the llms.txt file should look something like this:
# Website name
> Website name is an educational resource that provides guides, tutorials, and reference materials on a range of technical topics.
This site is maintained by a small team of independent contractors, and focuses on accuracy, clarity, and accessibility. We prioritize evergreen content and aim to support both beginners and professionals.
## Docs
- [Getting Started](https://websitename.com/getting-started): Introductory resources for new users.
## Optional
- [Team](https://websitename.com/team): Contributor bios and site background
Alternatively, tools like this llms.txt and llms-full.txt generator WordPress plugin and this llms.txt generator can also be used to generate llms.txt files.
Once complete, place the new llms.txt file in the website’s root directory. Then, ensure it's accessible at websitename.com/llms.txt.
Configure your server to add the following HTTP header for the llms.txt file:
X-Robots-Tag: llms-txt
It isn’t necessary, but it does help AI systems identify the purpose of the file and distinguish it from unrelated text files.
Verifying the llms.txt implementation involves three important steps:
If everything checks out, the llms.txt implementation is complete. Just remember to update it periodically to reflect any changes to the website structure or content, and keep an eye on best practices for implementing llms.txt. Since it’s still a new standard, the formatting and content could change over time.
Although it shares similarities with llms.txt, the llms-full.txt standard requires a slightly different approach, as it includes the full content of a site in one flattened file.
So, to give bots an even better understanding of a site, here’s how to get started with llms-full.txt.
To create an llms-full.txt file, use the following structure (in order), using markdown-style formatting in plain text:
The following sections are technically optional, but recommended for a comprehensive llms-full.txt file:
Since providing a comprehensive file with all of the above elements is beyond the scope of this article (it could go on for pages and pages), here is a brief example of an llms-full.txt file:
# Website name
> Website name is an educational resource that provides guides, tutorials, and reference materials on a range of technical topics.
This site is maintained by a small team of independent contractors, and focuses on accuracy, clarity, and accessibility. We prioritize evergreen content and aim to support both beginners and professionals.
## Table of Contents
- [Docs](#docs)
- [Optional](#optional)
## Docs
The Getting Started guide introduces new users to the basics of our platform, including account setup, key features, and navigation tips. It also includes frequently asked questions to help users troubleshoot common issues.
This section provides full installation steps for both Windows and macOS users, covering dependencies, configuration options, and known compatibility notes.
## Optional
We’re a distributed team of educators, developers, and technical writers. Learn more about our background and approach to content creation.
Llms-full.txt files can also be generated with the llms.txt and llms-full.txt generator WordPress plugin or this llms-full.txt generator.
Next, place the completed llms-full.txt file in your website’s root directory so it can be accessed at websitename.com/llms-full.txt.
To the website’s server configuration, add the following HTTP header for the llms-full.txt file:
X-Robots-Tag: llms-full-txt
As with llms.txt, this header is an optional addition. However, it can help LLMs figure out why the file is there and what it’s for.
Finally, see if the llms-full.txt implementation works by doing the following:
The llms-full.txt implementation should now be complete — at least, mostly. The only thing left to do would be to update it periodically to reflect any major site organization and content changes, or new best practices that may emerge involving llms-full.txt.
Although llms.txt and llms-full.txt contain lots of optional add-ons, these files tend to follow the same general format. However, this isn’t necessarily the case for ai.txt, at least as of this writing.
So, for simplicity, the following guide will be based strictly on the structure promoted by Spawning AI, one of the few companies actively promoting the standard.
Here’s how to get started with ai.txt.
To create an ai.txt file, the key is to use plain text formatting with directive-based syntax. The structure is generally similar to robots.txt but with added support for file-type wildcards and more granular control of what can and cannot be used for AI training.
Technically, there are no required elements for an ai.txt file. As long as the ai.txt file exists in the website’s root directory, it could be completely empty. However, this would have no effect and defeat the purpose of putting it there in the first place.
So, to create an effective ai.txt file, consider including the following elements:
Using the Spawning ai.txt generator, an example ai.txt file should look like this:
# Spawning AI
# Prevent datasets from using the following file types
User-Agent: *
Disallow: *.aac
Disallow: *.aiff
Allow: *.txt
Allow: *.pdf
If used, note that Spawning’s tool tends to block or allow entire categories, such as video or coding files. Feel free to remove file types as necessary to customize targeting.
After fine-tuning the file (if needed), upload it to the root directory of the website so it’s accessible at websitename.com/ai.txt.
To verify that the ai.txt file is working:
Once everything is verified, the ai.txt implementation is complete. As with the other web standards, remember to update it as necessary if targeted file preferences change or new best practices emerge.
Note that most AI systems don’t automatically detect these files — at least, not yet. Since these new web standards are still emerging and voluntary, manual input is often required.
So, to help AI tools recognize and apply files like llms.txt, llms-full.txt, and ai.txt, try one of the following:
Typically, doing just one of the above is enough for the tool to discover the file. However, if one method confuses the model or otherwise doesn’t seem to work, try combining two to improve results.
Since creating some of these files may seem like a lot of work (a comprehensive llms-full.txt file can be hundreds of thousands of words) and there’s no guarantee that AI will comply, it may seem like a waste of time.
However, there are some real benefits to implementing these emerging AI web standards:
Overall, files such as llms.txt, llms-full.txt, and ai.txt have the potential to provide site owners with more clarity and control over how AI interacts with their sites.
Don’t expect them to solve all AI-related scenarios, though. It’s easy to overestimate how much these files can really accomplish.
Although they may have their benefits, the new AI web standards also have their limits. Sure, they can help shape how AI systems interpret a website, but ultimately, they offer no guarantees.
Here’s what files like llms.txt, llms-full.txt, and ai.txt do not do:
Now, these limitations shouldn’t necessarily be dealbreakers. The new standards are, after all, new, so they’re not going to be perfect right out of the gate.
However, even with all the controversy and concern surrounding AI scraping and training (just look at the long list of OpenAI lawsuits), adoption has still been slow.
And interestingly, it’s not just due to technical gaps.
Although the limitations offer some insight into why it’s taking so long for people to adopt the new AI web standards, they’re really only one piece of the puzzle.
From confusion around what the files actually do to questions about whether they even work in the first place, here’s a look at why the adoption of llms.txt, llms-full.txt, and ai.txt may be so slow:
Ultimately, adoption of these new AI web standards is slow because there’s no good reason to use them. If early adopters had been reporting clear, measurable results, they should’ve gained some serious traction by now.
That said, momentum is building, as seen in our tracker. However, with such slow adoption, the question remains: will these truly become the new AI web standards?
Files like llms.txt, llms-full.txt, and ai.txt may not have hit the mainstream just yet, but they clearly have people talking. Although it's only based on a large subset of the web, our tracker does indicate that adoption is slow, but it’s not like it’s stagnant.
Whether or not these files end up becoming as commonplace as robots.txt will depend on several factors, with one of the most important being whether the companies behind AI bots and models start to take them seriously. After all, if all the major players are going to ignore them, then what’s the point?
For now, though, they are a step in the right direction. They may not be perfect, and they may not be enforceable, but they’re something. They offer site owners a way to tell AI companies how they want their content to be treated.
And in a world where AI is starting to play a role in how everyone is learning, searching, creating, and communicating, even the smallest tools for taking back some of that control are worth paying attention to.
At Originality.ai, we are an industry leader in AI detection and offer the most accurate AI detector for text generated by the latest LLMs. However, AI doesn’t just generate text; it generates images too. Now you can use our free AI image detector to maintain transparency about whether an image is AI-generated or created by humans.
As a student, getting a firm grasp on what your courses entail is important. However, it can be a little overwhelming when you have plenty of courses, assignments, and projects to keep track of. Syllabi can have non-essential details that distract from the primary information you need for studying and learning. With our new Syllabus Summarizer tool, you can quickly summarize the most important details to capture what you need to prioritize in a particular course!

AI & Plagiarism Detector for Serious Content Publishers
Originality.ai
64 Hurontario St
Collingwood, Ontario
L9Y 2L6














