AI Checker
Plagiarism Checker
Grammar Checker
Content Quality
Guideline Checker
Readability Checker
Fact Checker

Chrome Extension

In a March 2026 arXiv paper titled How LLMs Distort Our Written Language, researchers from Google DeepMind, UC Berkeley, the University of Washington, and more, explored how large language models (LLMs) such as ChatGPT, Claude, and Gemini can affect the meaning of human writing.
Their overall finding? LLMs can significantly change what we write.
Here’s a closer look at what they found.

In this study, researchers used three datasets:
Let’s take a closer look at each dataset below.
First, the researchers examined how people use LLMs when writing argumentative essays.
They recruited 100 native English-speaking participants in the US and asked them to write an argumentative essay that answered the question, “Does money lead to happiness?”
They divided the 100 participants into two groups:
Note: The researchers didn’t want to force a specific workflow. So, before beginning the study, they created two additional categories for participants. LLM-influenced for participants who self-reported generating 40% or less of their essay text, and whose transcripts supported that claim. LLM for participants who relied on AI more heavily.
That distinction reflects something important about AI-assisted writing: it doesn’t necessarily look the same for everyone.
Next, the researchers compared how LLMs and humans edited the same essays.
They started with a dataset of 86 argumentative essays written by university students in 2021 (the dataset was released in 2022, before the launch of ChatGPT).
For the original human-written dataset, each participant:
The researchers then built their own dataset of LLM-generated (gpt-5-mini, gemini-2.5-flash, and claude-haiku) D2 drafts using D1 essays.
The researchers also prompted the LLMs to perform different revisions:
This setup allowed the researchers to compare LLM-revised essays to human revisions.
To better understand LLM use in a real-world setting, the researchers initially looked at 75,000 peer reviews from the International Conference on Learning Representations (ICLR) 2026.
Since the ICLR review process doesn’t allow AI, the reviewers would likely write original, high-quality reviews, or the study acknowledged they might at least hide any LLM use as much as possible.
Of the 75,000 reviews:
The researchers analyzed 18,000 of the ICLR 2026 peer reviews across 9,000 papers using the LLM-as-a-Judge classifier to compare the scores/evaluations of strengths/weaknesses of AI reviews vs. human reviews.
The researchers made a point of using only papers with one review entirely written by humans and one LLM-generated review to help control for potential bias.
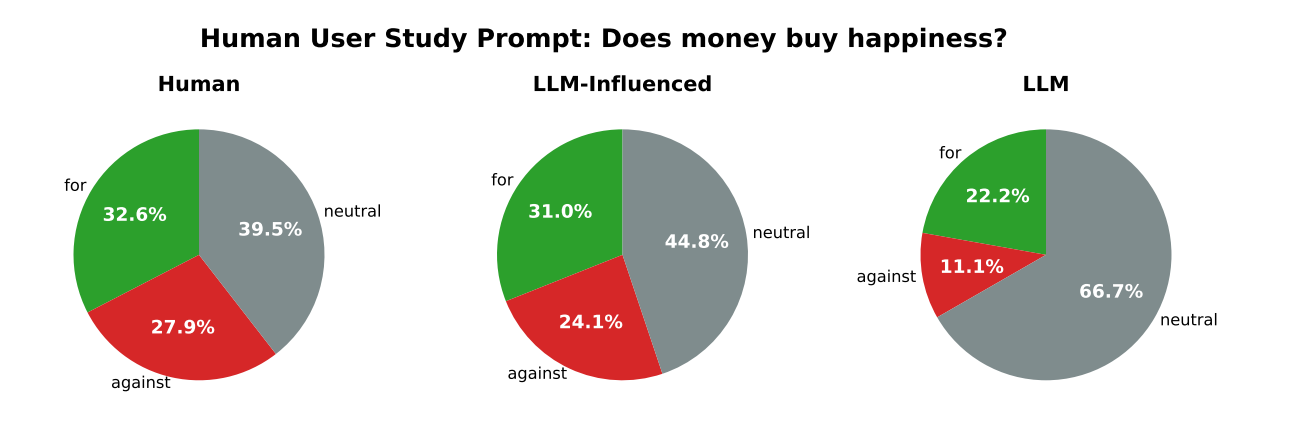
Participants who heavily relied on LLMs were most likely to produce neutral essays.
Essays produced by heavy LLM users were much less likely to take a strong position for or against the topic than those written entirely by humans.
Further, the researchers found that even when an LLM was prompted to just make some minimal edits (using the second dataset), such as grammar editing, it often ended up changing the conclusion or argumentative claim made in the essay (more on that below - see finding 3).
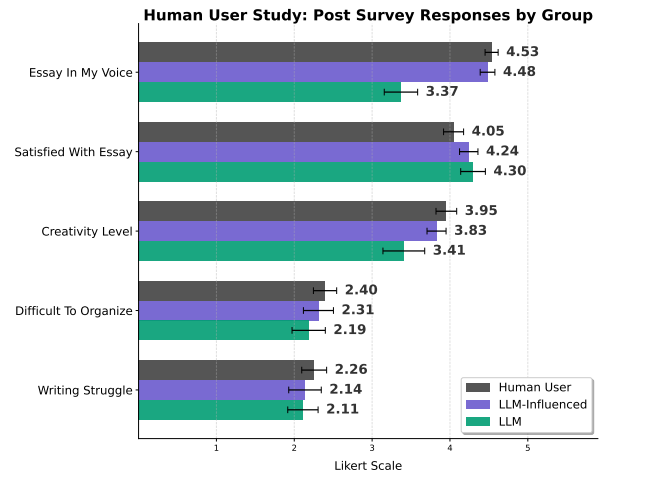
Heavy LLM users reported their essays were less creative and less in their own voice than those in the human and LLM-influenced groups.
However, they still reported comparative (or higher) satisfaction with the final essay.
This suggests that people recognize the extensive use of LLMs can result in a loss of voice and creativity in their writing, yet they still find the AI support for navigating writing struggles, such as organization, beneficial.
With the ArgRewrite-v2 dataset, researchers noticed a significant difference between human and LLM revisions.
While humans tend to make small shifts while editing, LLMs tend to change the essay’s meaning.
“The uniformity of these shifts across different LLMs also suggests a convergence toward LLM-preferred linguistic patterns… that may not reflect the original intent or voice of human writers.” - Study
So, LLMs were actually shifting diverse human writing styles for the essays and pushing them toward a “shared semantic mode.” As a result they pieces were less reflective of the writer’s voice.
This happened even when the prompt for the LLM was grammar edits.
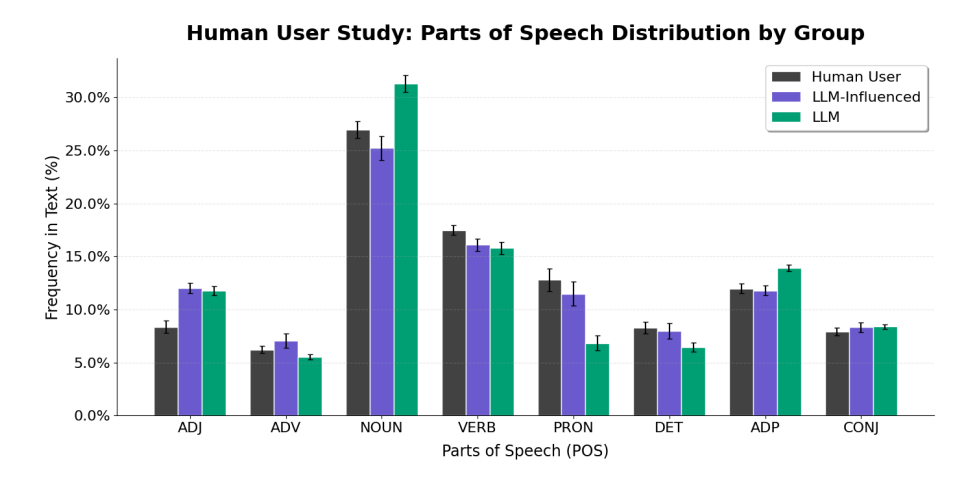
Perhaps unsurprisingly, LLM edits didn’t just change the meaning of essays. They also changed how the essays were written at multiple levels.
The researchers found that LLMs:
These findings suggest that LLM use changed both what essays said and how they said it. Often, it made the writing more standard and less reflective of individual voice or experience.
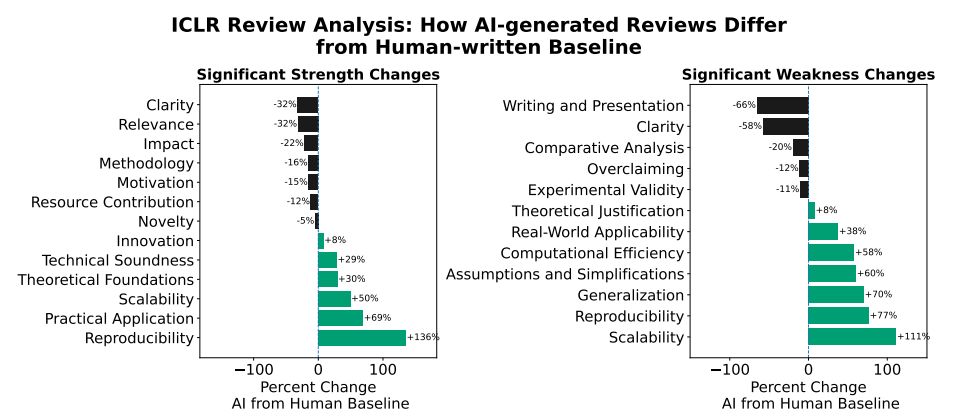
With the ICLR 2026 dataset, the researchers found that LLM use in peer reviews can shift the final decisions, arguments, and even scores.
Not only do LLMs tend to give slightly higher scores than humans (“LLMs assign scores 10% higher than humans”), but their reviews also tend to comment on different strengths and weaknesses in scientific papers.
While humans are more likely to comment on relevance of research and paper clarity, LLMs are much more likely to mention scalability and reproducibility as strengths and weaknesses.
The biggest takeaway from this study is that heavy LLM use may not just change how we write, but also what our writing says.
That has implications for just about anyone who may choose to use AI to help with their written work, including writers, marketers, educators, students, and researchers.
Sure, AI can make writing easier and faster; however, if that convenience comes at the cost of more standardized language, softer or shifted stances on issues, and less individual voice and creativity, then the tradeoffs may not be something that every writer is comfortable with.
Maintain transparency in what you’re writing with Originality.ai’s AI Checker.
Then, try out Deep Scan to find out how you can ethically make writing sound more human.
Further reading:
With the release of OpenAI’s new model for AI-generative text, we needed to re-check Originality.AI’s accuracy. Essentially we completed a study to identify if the AI developed at Originality.AI can detect if the content that was produced by ChatGPT, GPT 3.5 (DaVinci-003) with the same accuracy as it can for GPT-3 which is 94%.
GPTZero is an artificial intelligence (AI) content detection tool created by Princeton University student Edward Tian. It was launched in January 2023, just months after the release of ChatGPT in November 2022. Learn about GPTZero, its 2026 acquisition by Superhuman (Grammarly), and how it works in this GPTZero review.

AI & Plagiarism Detector for Serious Content Publishers
Originality.ai
64 Hurontario St
Collingwood, Ontario
L9Y 2L6















